Data Science Lifecycle¶
In our data science projects, we follow the data science lifecycle process proposed in the “cross industry standard process for data mining (CRISP-DM)” from Wirth and Hipp [2000]
Note
To learn more about this framework, review this presentation about the CRISP-DM.
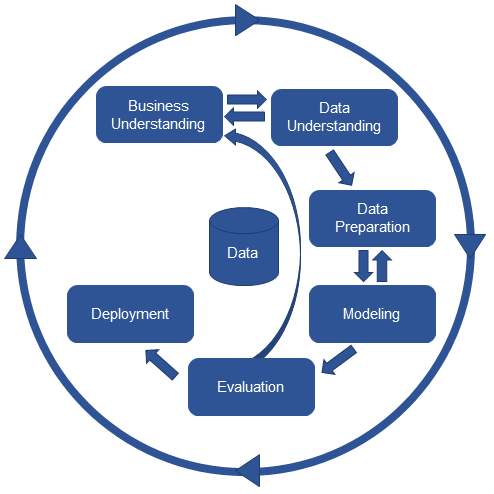
Next, we show the most crucial steps of the framework.
Business understanding¶
Define your (business) goal
Frame the problem (regression, classification,…)
Choose a performance measure (RMSE, …)
Show the data processing components (data pipeline)
Data understanding¶
Import data
Clean data
Format data properly (numeric or categorical)
Create new variables
Overview about the complete data
Split data into training and test set using stratified sampling
Discover and visualize the data to gain insights (on a copy of the training data)
Data preparation¶
Perform feature selection (choose predictor variables)
Do feature engineering (mainly with
recipes)Create a validation set from the training data (e.g., with k-fold crossvalidation)
Modeling¶
Specify the models
Bundle the data preprocessing recipe and model in a
workflowCompare model performance on the validation set
Pick the model that does best on the validation set
Train your best model with all of the training data
Double-check that model against the test set.