t-Test¶
A t-test can be used to determine if there is a systematic difference between the means of two groups.
The simplest form of analysis that can be done is one with only one independent variable (outcome variable) that is manipulated in only two ways (group variable) and only one outcome is measured. The manipulation of the independent variable typically involves having an experimental condition and a control:
E.g., does the introduction of a new UX feature on a website lead to a higher revenue than the old one? We then could measure revenue for both conditions and compare them. This situation can be analysed with a t-test.
Furthermore, we can use a t-test to draw conclusions from model estimates. In particular, the test can be used to decide whether there is any significant relationship between a dependent variable y and a feature x by testing the null hypothesis that the regression coefficient b equals 0.
Among the most frequently used t-tests are:
Dependent t-test: Compares two means based on related data.
Independent t-test: Compares two means based on independent data
Significance testing: Testing the significance of the coefficient b in a regression.
Independent t-test example¶
Let’s conduct an independent two-sample t-test for the following hypothetical research question for an e commerce online shop:
Does the introduction of a new UX feature increases the time on site?
We proceed as follows:
Imagine that we split a random sample of 1000 website members into two groups using random assignment. Random assignment ensures that, on average, everything else is held constant between the two groups.
Group “A” (500 members) receives the current product experience
Group “B” (500 members) receives some change that we think is an improvement to the experience.
We then compare metrics (time on site) between the two groups.
Let’s formulate a nullhypothesis (\(H_0)\):
\(H_0\) “There is no difference in the time spent on site between the two groups.”
Generate data¶
We generate our own data for this example.
from scipy import stats
# number of participants
n_A = 500 # see old feature
n_B = 500 # see new feature
# generate random data with scipy
np.random.seed(123)
# mean =loc and standard deviation = scale
ux_new = stats.norm.rvs(loc=4.0, scale=1.2, size = n_B)
ux_old = stats.norm.rvs(loc=3.8, scale=1.5, size = n_A)
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
/var/folders/9c/_3s5jt3n60j__flsgl0t72340000gn/T/ipykernel_5199/3028268425.py in <module>
6
7 # generate random data with scipy
----> 8 np.random.seed(123)
9
10 # mean =loc and standard deviation = scale
NameError: name 'np' is not defined
import pandas as pd
# create pandas DataFrame
df = pd.DataFrame({'ux_new': ux_new, 'ux_old': ux_old})
df.head(5)
| ux_new | ux_old | |
|---|---|---|
| 0 | 2.697 | 4.928 |
| 1 | 5.197 | 3.904 |
| 2 | 4.340 | 3.402 |
| 3 | 2.192 | 5.194 |
| 4 | 3.306 | 5.691 |
import seaborn as sns
%matplotlib inline
sns.set_style("whitegrid")
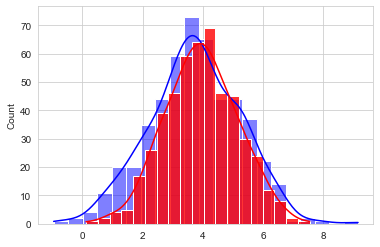
sns.histplot(x=ux_old, data=df, color="blue", label="UX old", kde=True)
sns.histplot(x=ux_new, data=df, color="red", label="UX new", kde=True, alpha=0.8);
Calculate t-statistic¶
The t-statistic is used in a t-test to determine whether to support or reject the null hypothesis. The formula of the statistic is:
where \(s_p\) is the pooled standard deviation:
Thus, the t statistic as a way of quantifying how large the difference between groups is in relation to the sampling variability of the difference between means.
Note that we perform the calculation of the t-Test manually to better understand the concept.
Usually we would just use the independent t-test function below and are done:
t, p = stats.ttest_ind(ux_new, ux_old)
print("t =", t)
print("p =", p)
t = 2.49205054533012
p = 0.012862137872711413
First of all, let`s calculate the different components of the formula. We will start with the numerator of the formula.
Difference in mean¶
Calculate the differeence between the two means:
diff_mean = ux_new.mean() - ux_old.mean()
print(round(diff_mean,2))
0.21
Pooled standard deviation¶
Next, we calculate the variance:
and standard deviation:
We use the numpy function var with the optional argument ddof which means “Delta Degrees of Freedom” (the divisor used in the calculation of the variance is (N - ddof), where N represents the number of elements. By default ddof is zero).
Note that ddof is equal to the number of parameters we use. We estimate the mean, therefore we only have one parameter. See this documentation for more information.
import numpy as np
# calculate variance
var_ux_new = ux_new.var(ddof=1)
var_ux_old = ux_old.var(ddof=1)
print("Variance:")
print("UX new:", var_ux_new, "UX old:", var_ux_old)
# calculate standard deviation
s_ux_new = np.sqrt(var_ux_new)
s_ux_old = np.sqrt(var_ux_old)
print("Standard deviation:")
print("UX new:", s_ux_new, "UX old:", s_ux_old)
Variance:
UX new: 1.452143284234209 UX old: 2.247145174966161
Standard deviation:
UX new: 1.2050490795956026 UX old: 1.499048089610924
Now we calculate the pooled variance (also known as combined variance, composite variance, or overall variance) to estimate the combined variance of our two groups:
Afterwards, we take the square root to get the pooled standard deviatin (\({s}_p\))
# calculate pooled variance
var_p = ( (n_B - 1) * var_ux_new + (n_A - 1) * var_ux_old ) / ( n_A + n_B - 2 )
var_p
1.849644229600185
# pooled standard deviation
s_p = np.sqrt(var_p)
s_p
1.3600162607852102
Calculate t-statistic¶
# calculate t-statistic
t = (diff_mean) / (s_p * np.sqrt(2/500))
t
2.49205054533012
The probability density function for t is (see documentation and wikipedia):
## Compare with the critical t-value
df = n_A + n_B - 2 # Degrees of freedom
crit_t = stats.t.cdf(t, df=df)
print(crit_t)
0.9935689310636443
#p-value after comparison with the t
p = 1 - crit_t
print(p)
0.006431068936355699
print('t =', t)
print('p=', 2*p)
t = 2.4921
p= 0.0129
Note that we multiply the p value by 2 because it’s a two tailed t-test.
You can see that after comparing the t statistic with the critical t value (computed internally) we get a good p value way below 5% and thus we reject the null hypothesis.
This means we have an indication that the mean of the two distributions are different and statistically significant.