Fallstudie 3
Contents
Fallstudie 3#
Die Fallstudie ist eine individuelle Prüfungsleistung und darf nicht gemeinsam in einer Gruppe bearbeitet werden.
Hinweise zur Bearbeitung der Fallstudie:
Sie wurden kürzlich von dem E-Commerce-Händler, der Ihnen in Fallstudie 1 zugewiesen wurde (siehe Moodle), im Bereich Online-Marketing eingestellt.
Ihr Aufgabenbereich umfasst unter anderem Themen mit Bezug zu Data-Driven-Marketing. Ihre Vorgesetzte hat bereits einige Projekte für Sie vorbereitet und möchte in einer Präsentation über die Ergebnisse informiert werden. Sie interessiert sich dabei auch insbesondere für die von Ihnen gewählte Vorgehensweise, weshalb Sie dise ebenfalls ausführlich in der Präsentation darstellen sollen.
Neben der Präsentation möchte Ihre Vorgesetzte auch jeweils den Code in Form eines ausführlich kommentierten Jupyter Notebooks erhalten. Die Notebooks sollen zudem an einen Kollegen übergeben werden, der mit Hilfe Ihrer Arbeit weitere Analysen durchführen soll. Dafür muss er die von Ihnen erstellten Inhalte komplett nachvollziehen können.
Sie können die Präsentation und Notebooks in Deutsch oder Englisch erstellen.
1. Web Scraping & Data Management (30%)#
Für künftige Wettbewerbsanalysen soll das Potenzial von Web Scraping ermittelt werden. Dafür soll zunächst testweise die eigene Seite gescrapt werden.
Hinweis: falls die Seite Ihres E-Commerce-Händlers aufgrund technischer Gegebenheiten nicht gescrapt werden kann, können Sie die Seite eines geeigneten Wettbewerbers (oder Forums) auswählen. Erläutern Sie in diesem Fall, weshalb das Scraping nicht möglich war und weshalb Sie sich für den entsprechenden Wettbewerber entschieden haben. Erstellen Sie in jedem Fall einen Screenshot der gescrapten Seite und markieren Sie die Inhalte, die von Ihnen gescrapt wurden.*
Wählen Sie eine Webseite, auf welcher mehrere Produkte aufgelistet werden.
Scrapen Sie 2-4 beliebige Inhalte wie bspw.:
Bezeichnung des Produkts
Produktbeschreibung
Preis
Kommentare
Anzahl der Kundenbewertungen
Kundenbewertung (Durchschnittsbewertung oder ähnliches)
…
Bereinigen Sie die Daten mit Hilfe von Pandas so gut wie möglich und erstellen Sie einen “sauberen” DataFrame
Speichern Sie den Notebook mit der Bezeichnung
webscraping.ipynb
Da die Inhalte in Zukunft regelmäßig gescrapt und für unterschiedliche Zwecke dem gesamten Unternehmen zur Verfügung gestellt werden sollen, müssen die bereinigten Daten in einer relationalen Datenbank (PostgreSQL) abgespeichert werden:
Einige Inhalte der gescrapten Inhalte sollen als bereinigte Daten direkt in einer (lokalen) PostgreSQL-Datenbank abgespeichert werden.
Speichern Sie (ausgewählte Inhalte) des Pandas DataFrame in eine Tabelle mit der Bezeichnung
produkteSpeichern Sie den Notebook mit der Bezeichnung
webdaten_erstellung.ipynb
Hinweise zu Pandas
die Erstellung der Datenbank ist nicht mehr notwendig: [Erstellen Sie dafür eine Datenbank mit der Bezeichnung
webdaten]
Aufgrund der Schwierigkeiten bei dem Sraping müssen die folgenden Inhalte nicht bearbeitet werden:
[Führen Sie in einem neuen Notebook beispielhafte Datenbank-Abfragen durch (d.h. stellen Sie in einem Notebook eine Verbindung mit der Datenbank her) und erstellen Sie folgende Analysen (mit Python oder SQL): - Anzahl der einzigartigen ("unique") Produkte - Durchschnittspreis aller Produkte - Identifikation des höchsten Preise - Identifikation des geringsten Preises - Speichern Sie den Notebook mit der Bezeichnung `webdaten_abfrage.ipynb`]Predictive Analytics (70%)#
Die beiden folgenden Projekte sollen für eine Ihrer E-Commerce-Seiten in den USA durchgeführt werden. Die dort zuständige Kollegin hat die folgenden Briefings für Sie erstellt. Am Ende des Briefings finden Sie Hinweise zu den Daten.
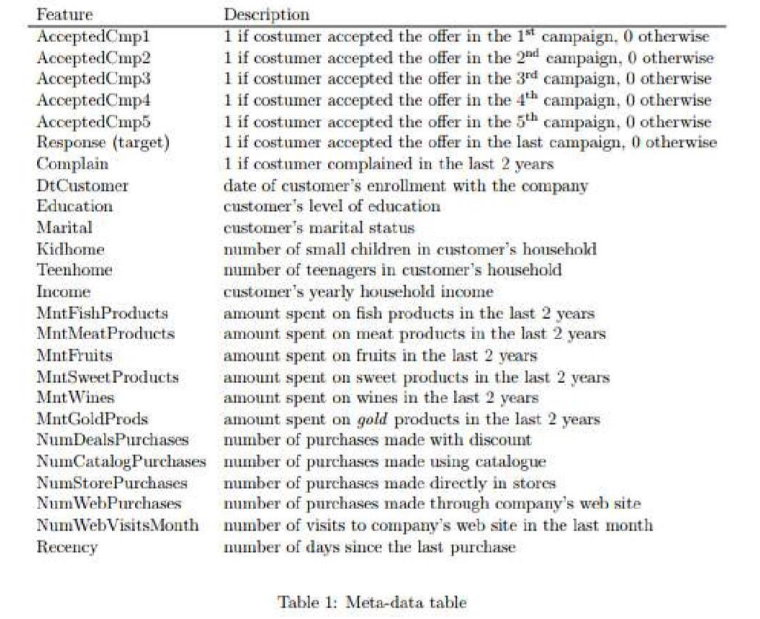
Wichtiger Hinweis zu den Daten: für die Modellierung sind nicht alle Daten relevant. Sie müssen sich daher entscheiden (mit Hilfe der explorativen Analyse), welche Variablen in das Modell aufgenommen werden sollen, und welche nicht. Als Hilfestellung finden Sie ganz unten auf dieser Seite einige Erklärungen zu den wichtigsten Variablen in dem Datensatz.
Classification model#
The objective is to build a predictive model that will produce high profits for the next direct marketing campaign, scheduled for the next month.
The new campaign, sixth, aims at selling a new gadget to our customers. To build the model, a pilot campaign involving 2.240 customers was carried out. The customers were selected at random and contacted by phone regarding the acquisition of the gadget. During the following months, customers who bought the offer were properly labeled (we called the variable Response).
The objective is to develop a model that predicts customer behavior and to apply it to the rest of the customer base. Hopefully the model will allow us to cherry pick the customers that are most likely to purchase the offer while leaving out the non-respondents, making the next campaign highly profitable.
Moreover, other than maximizing the profit of the campaign, the Chief Marketing Officer (CMO) is interested in understanding to study the characteristic features of those customers who are willing to buy the gadget.
Perform data exploration to gain an understanding of the data. Explain your findings.
Find differences between customers who accepted the offer and those who don’t. Explain your findings.
For the new campaign develop a predictive model that classifies if the customer will accept the offers or not (use a train test split).
Evaluate your model with relevant metrics. Explain your findings.
Regression model#
For our upcoming direct maarketing campaigns for wine, we need a model to predict the amount new customers will spend on wine in the next two years. Use the same data as before to train a model on our customer’s wine spending for the last two years (variable MntWines).
Develop a regression model to predict the variable
MntWines(use a train test split).Evaluate your model with relevant metrics.
Explain your findings.
Data#
The data set
commerce.csvconsists of 2206 customers with data on:Customer profiles
Product preferences
Campaign successes/failures
Channel performance
You can find the data in this GitHub-repo. Use the link to import the CSV with Pandas.
Data description of the most relevant variables: