Logistic Regression
Contents
Logistic Regression#
We use a classification model to predict which customers will default on their credit card debt.
Data#
To learn more about the data and all of the data preparation steps, take a look at this page. Here, we simply import the prepared data:
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/kirenz/classification/main/_static/data/default-prepared.csv')
# preparation of label and features
y = df['default_Yes']
X = df.drop(columns = 'default_Yes')
Data split#
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state = 1)
Model#
from sklearn.linear_model import LogisticRegression
clf = LogisticRegression()
clf.fit(X_train, y_train)
LogisticRegression()In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
LogisticRegression()
y_pred = clf.predict(X_test)
# Return the mean accuracy on the given test data and labels:
clf.score(X_test, y_test)
0.968
Confusion matrix#
from sklearn.metrics import ConfusionMatrixDisplay
ConfusionMatrixDisplay.from_estimator(clf, X_test, y_test);
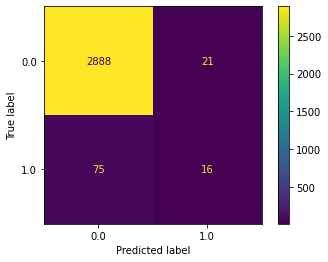
Classification report#
from sklearn.metrics import classification_report
print(classification_report(y_test, y_pred, target_names=['0', '1']))
precision recall f1-score support
0 0.97 0.99 0.98 2909
1 0.43 0.18 0.25 91
accuracy 0.97 3000
macro avg 0.70 0.58 0.62 3000
weighted avg 0.96 0.97 0.96 3000
ROC Curve#
from sklearn.metrics import RocCurveDisplay
RocCurveDisplay.from_estimator(clf, X_test, y_test);
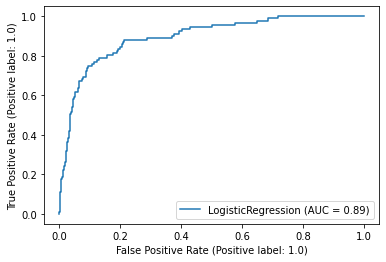
AUC Score#
from sklearn.metrics import roc_auc_score
roc_auc_score(y_test, clf.decision_function(X_test))
0.8946921074800072
y_score = clf.predict_proba(X_test)[:, 1]
roc_auc_score(y_test, y_score)
0.8946921074800072
Change threshold#
Use specific threshold
# obtain probabilities
pred_proba = clf.predict_proba(X_test)
# set threshold to 0.25
df_25 = pd.DataFrame({'y_test': y_test, 'y_pred': pred_proba[:,1] > .25})
ConfusionMatrixDisplay.from_predictions(y_test, df_25['y_pred']);
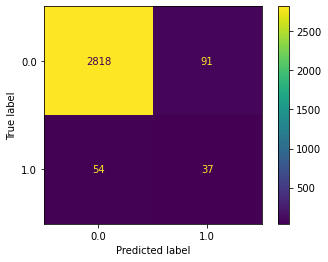
Classification report#
print(classification_report(y_test, df_25['y_pred'], target_names=['0', '1']))
precision recall f1-score support
0 0.98 0.97 0.97 2909
1 0.29 0.41 0.34 91
accuracy 0.95 3000
macro avg 0.64 0.69 0.66 3000
weighted avg 0.96 0.95 0.96 3000