Basics¶
Big data refers to data that is so large, complex or fast that it’s difficult or impossible to store or process using traditional methods. These characterisitcs are also known as the three V’s:
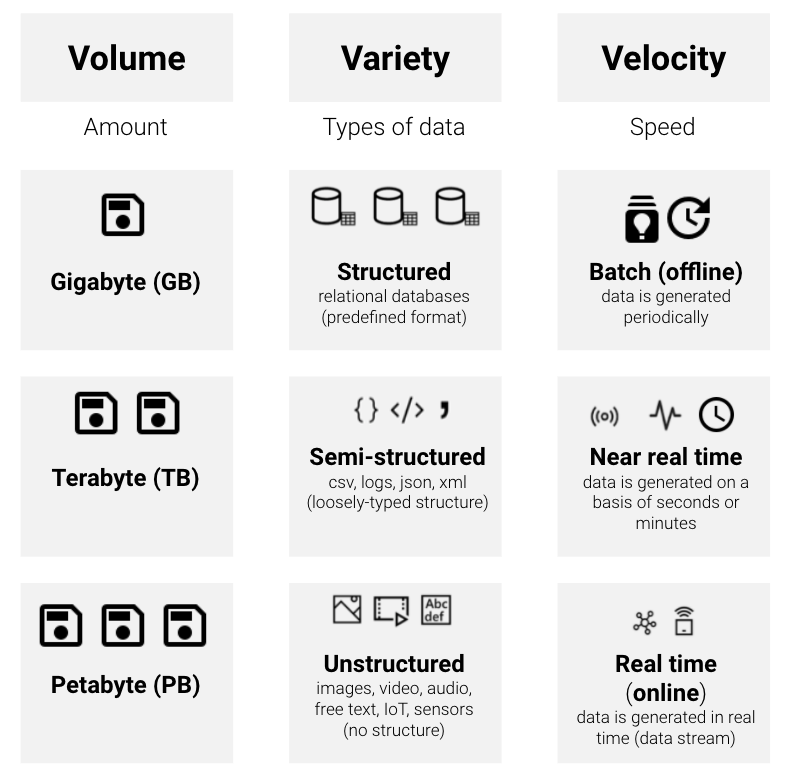
Volume: Organizations collect data from a variety of sources, ranging from gigabytes to petabytes. Frameworks like the Hadoop Distributed File System (HDFS) for storing data and Apache Spark for cluster computing provide solutions to handle large amounts of data.
Variety. Data comes in all types of formats – from structured data in relational database management systems (RDBMS) like PostgreSQL to loosely-typed semi-structured and unstructured data like text documents, emails, videos and audio data which can be stored in NoSQL databases.
Velocity. A standard data scenario is batch processing of data at rest. This means source data is loaded (periodically) into data storage, either by the source application itself or by an orchestration workflow. Batch processing is used in a variety of scenarios, from simple data transformations to a more complete ETL (extract-transform-load) pipeline. With the growth in the Internet of Things, data now streams into businesses at an higher speed and often has to be handled with in (near) real time.