Hadoop ecosystem¶
The Apache Hadoop software library is a big data framework that allows for the distributed storing and processing of large data sets.
The Apache Software Foundation provides several open source big data libraries, but here we will mainly focus on the Hadoop Distributed File System, which is a distributed file system for storing large data sets (a typical file in HDFS is gigabytes to terabytes in size):

Picture source: Du (2018)
HDFS follows the Master-Slave architecture pattern. Two sub-components, namely NameNode and DataNode, are present in master and slave nodes respectively (Tomcy & Pankaj, 2017):
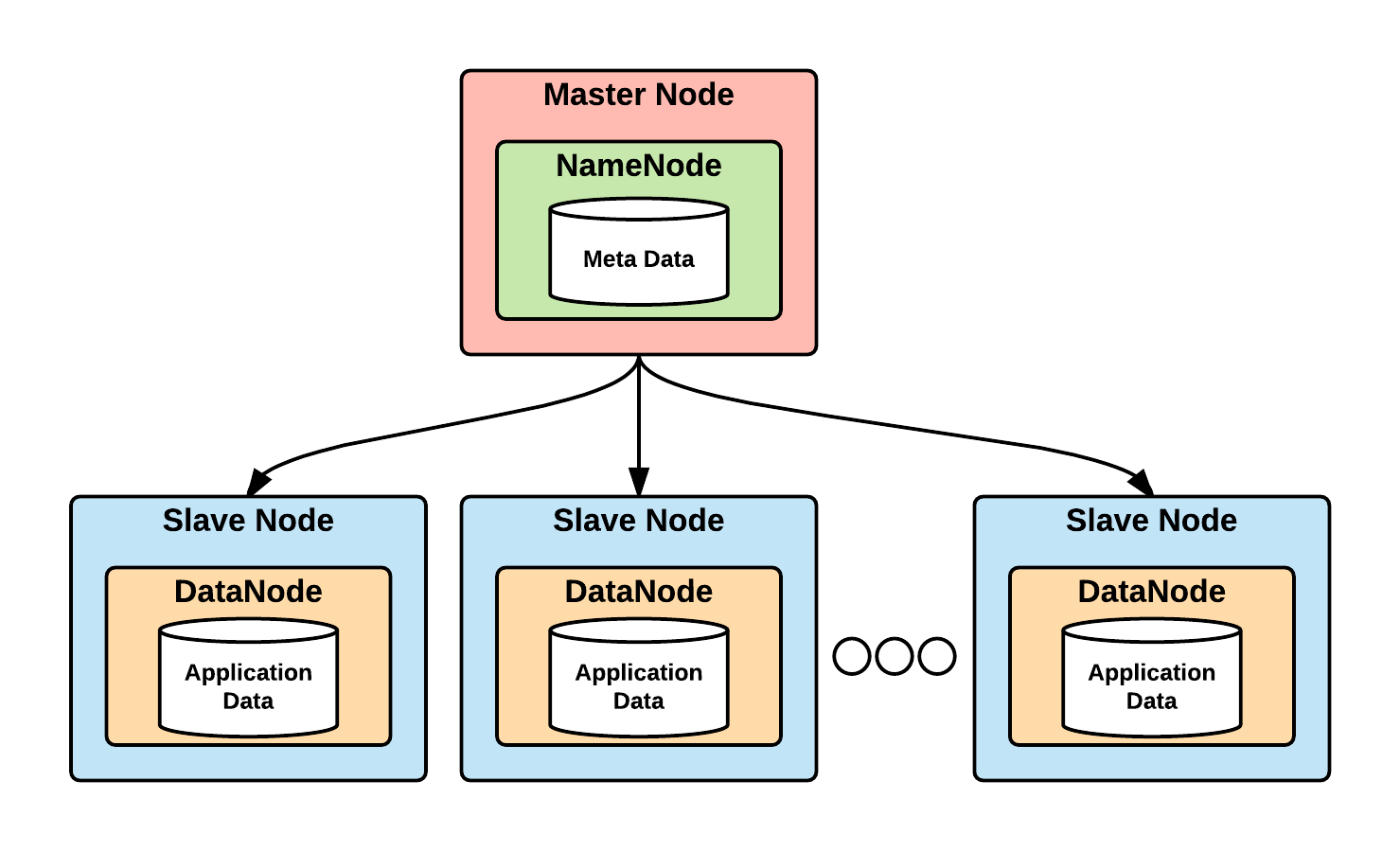
The DataNode stores the application data and NameNode stores the filesystem metadata. The communication between NameNode and DataNode is through TCP-based protocols and is quite reliable and high-performant.