Delta Lake¶
Delta lake is an open-source project that enables building a Lakehouse Architecture on top of existing storage systems such as S3, ADLS, GCS, and HDFS.
Watch this presentation from Michael Armbrust, head of Delta Lake engineering team, to learn how his team built upon Apache Spark to bring ACID transactions and other data reliability technologies from the data warehouse world to cloud data lakes.
After watching this video, you should be able to answer the following questions:
Questions
What is the role of Apache Spark in big data processing?
How to use data lakes as an part of the data architecture?
What are data lake reliability challenges?
How does Delta Lake helps provide reliable data for Spark processing?
What are specific improvements that Delta Lake adds?
Paper: see Armbrust et al. [2020]
Productionizing Machine Learning with Delta Lake¶
Productionizing Machine Learning with Delta Lake by Brenner Heintz and Denny Lee:
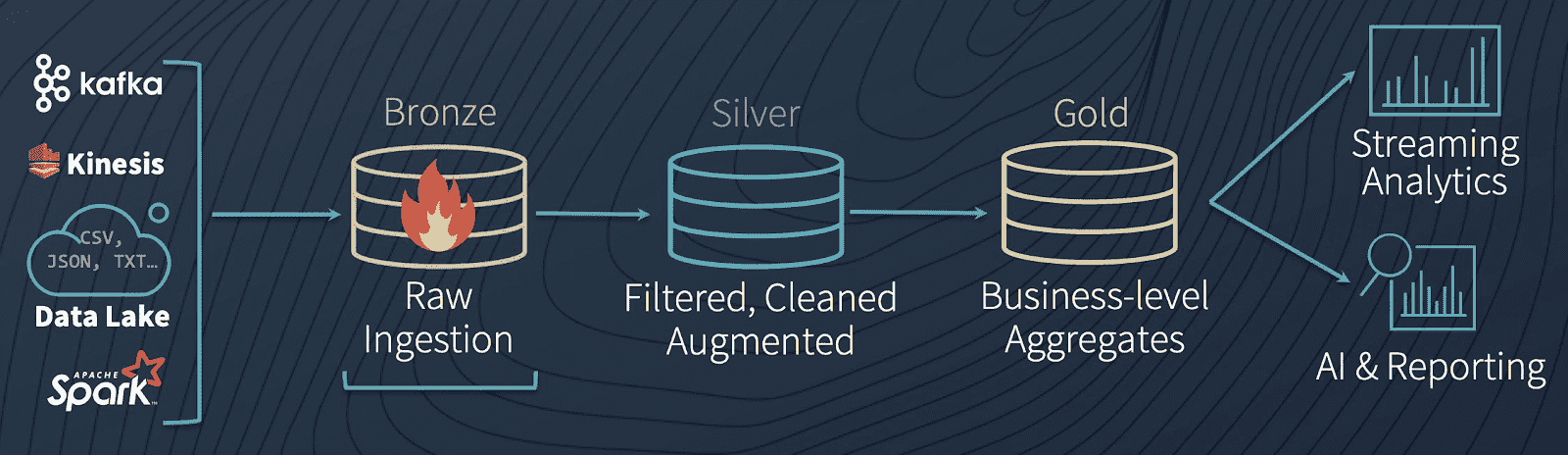
Questions
What is schema enforcement and schema evolution?
Explain the concept of time travel, a.k.a. data versioning.
What is a so called “multi-hop” architecture?
How does Delta Lake helps provide reliable data for Spark processing?
What are specific improvements that Delta Lake adds?
Structured streaming¶
Structured Streaming is a scalable and fault-tolerant stream processing engine built on the Spark SQL engine. You can express your streaming computation the same way you would express a batch computation on static data. The Spark SQL engine will take care of running it incrementally and continuously and updating the final result as streaming data continues to arrive. You can use the Dataset/DataFrame API in Scala, Java, Python or R to express streaming aggregations, event-time windows, stream-to-batch joins, etc. To learn more, visit the Apache Spark Structured Streaming Programming Guide.
Delta Lake provides a way to store structured data because it is a open-source storage layer that brings ACID transactions to Apache Spark and big data workloads Together, these can make it very easy to build pipelines in many common scenarios.