Apache Spark¶
Apache Spark is a multi-language (Python, SQL, Scala, Java or R) engine for executing data engineering, data science, and machine learning on single-node machines or clusters. It supports a wide range of applications, including ETL, machine learning, stream processing, and graph computation.
At its core, Spark is a “computational engine” that is responsible for scheduling, distributing, and monitoring applications consisting of many computational tasks across many worker machines, or a computing cluster. One of the main features Spark offers for speed is the ability to run computations in memory. It uses so called resilient distributed datasets (RDDs), which are Spark’s main programming abstraction.
Like HDFS, Spark uses a Master-Slave architecture. It has one central coordinator (Driver) that communicates with many distributed workers (executors). The driver and each of the executors run in their own Java processes:
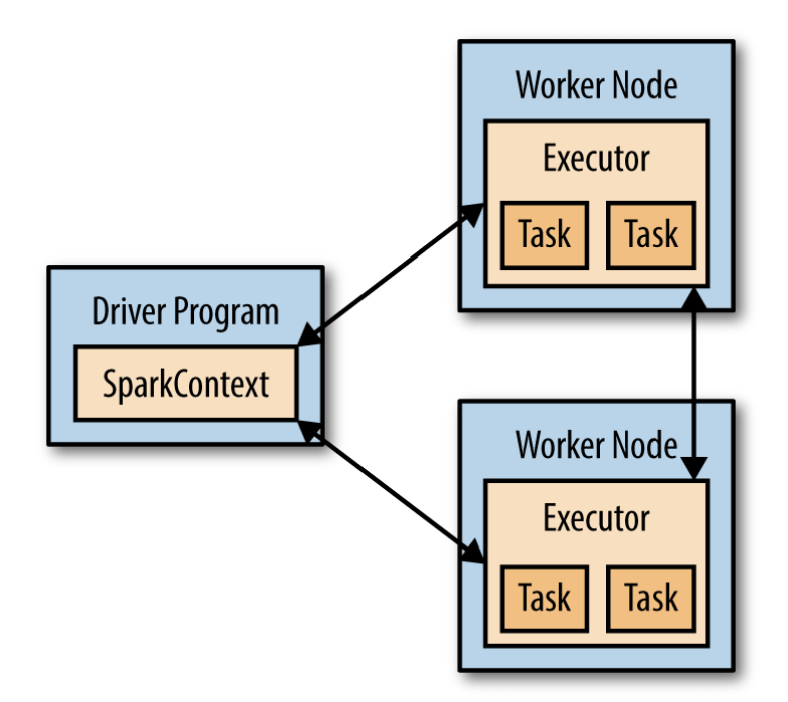
Picture source: Karau et al. [2015]
The driver is the process where the main method runs. First it converts the user program into tasks and after that it schedules the tasks on the executors.
Executors are worker nodes’ processes in charge of running individual tasks in a given Spark job. They are launched at the beginning of a Spark application and typically run for the entire lifetime of an application. Once they have run the task they send the results to the driver. They also provide in-memory storage (see Stackoverflow for more details).
Spark can run over a variety of cluster managers, including Hadoop YARN, Apache Mesos, and a simple cluster manager included in Spark itself called the Standalone Scheduler. Note that Spark does not require Hadoop - it simply has also support for storage systems implementing the Hadoop APIs.
Spark in Python¶
PySpark is an interface for Apache Spark in Python. It not only allows you to write Spark applications using Python APIs, but also provides the PySpark shell for interactively analyzing your data in a distributed environment.
PySpark supports most of Spark’s features such as Spark SQL, DataFrame, Streaming, MLlib (Machine Learning) and Spark Core.
Spark in R¶
SparkR is a R package from Apache Spark that provides a light-weight frontend to use Spark in R. In Spark 3.2.0, SparkR provides a distributed data frame implementation that supports operations like selection, filtering, aggregation etc. (similar to R data frames, dplyr) but on large datasets. SparkR also supports distributed machine learning using MLlib.
An alternative to SparkR is sparklyr, an interface for Apache Spark provided by RStudio. With sparklyr you can use all of the available dplyr verbs against the tables within a cluster.
Spark in Databricks¶
Databricks is a software company founded by the creators of Apache Spark. It offers a paid cloud-based big data platform for working with Spark, that includes automated cluster management and Jupyter Notebook-style notebooks:
The Databricks Community Edition is the free version of the platform. Its users can access a micro-cluster as well as a cluster manager and notebook environment: