IMDB Sentiment analysis
Contents
IMDB Sentiment analysis#
This tutorial is based on An Introduction to Keras Preprocessing Layers by Matthew Watson, Text classification with TensorFlow Hub: Movie reviews and Basic text classification by TensorFlow.
Main topics in this tutorial:
Build a binary sentiment classification model with keras
Use keras layers for data preprocessing
Use TensorBoard to view model results
Save and reload the model
Example for multiple feature engineering steps
Prerequisites#
To start this tutorial, you need the following setup:
Install TensorFlow (Note that we install TensorFlow Extended to obtain more deployment options. However, we don’t use the options in this tutorial)
Setup#
import tensorflow as tf
from tensorflow import keras
import tensorflow_datasets as tfds
from tensorflow.keras import layers
from tensorflow.keras import losses
from keras.models import load_model
from tensorboard import notebook
import matplotlib.pyplot as plt
import datetime
print("Version: ", tf.__version__)
Version: 2.7.1
# Load the TensorBoard notebook extension
%load_ext tensorboard
Data#
We use the IMDB dataset with 50,000 polar movie reviews (positive or negative)
Training data and test data: each 25,000
Training and testing sets are balanced (they contain an equal number of positive and negative reviews)
The input data consists of sentences (strings)
The labels to predict are either 0 or 1.
Data import#
We use 3 data splits: training, validation and test data
Split the data into 60% training and 40% test
Split training into 60% training and 40% validation
Resulting data split:
15,000 examples for training
10,000 examples for validation
25,000 examples for testing
train_ds, val_ds, test_ds = tfds.load(
name="imdb_reviews",
split=('train[:60%]', 'train[60%:]', 'test'),
as_supervised=True)
2022-04-08 09:30:11.503633: I tensorflow/core/platform/cpu_feature_guard.cc:151] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
Explore data#
Each example is a sentence representing the movie review and a corresponding label.
The sentence is not preprocessed in any way.
The label is an integer value of either 0 or 1
0 is a negative review
1 is a positive review.
Let’s print first 2 examples.
for x, y in train_ds.take(2):
print("Input:", x)
print(50*".")
print("Target:", y)
print(50*"-")
Input: tf.Tensor(b"This was an absolutely terrible movie. Don't be lured in by Christopher Walken or Michael Ironside. Both are great actors, but this must simply be their worst role in history. Even their great acting could not redeem this movie's ridiculous storyline. This movie is an early nineties US propaganda piece. The most pathetic scenes were those when the Columbian rebels were making their cases for revolutions. Maria Conchita Alonso appeared phony, and her pseudo-love affair with Walken was nothing but a pathetic emotional plug in a movie that was devoid of any real meaning. I am disappointed that there are movies like this, ruining actor's like Christopher Walken's good name. I could barely sit through it.", shape=(), dtype=string)
..................................................
Target: tf.Tensor(0, shape=(), dtype=int64)
--------------------------------------------------
Input: tf.Tensor(b'I have been known to fall asleep during films, but this is usually due to a combination of things including, really tired, being warm and comfortable on the sette and having just eaten a lot. However on this occasion I fell asleep because the film was rubbish. The plot development was constant. Constantly slow and boring. Things seemed to happen, but with no explanation of what was causing them or why. I admit, I may have missed part of the film, but i watched the majority of it and everything just seemed to happen of its own accord without any real concern for anything else. I cant recommend this film at all.', shape=(), dtype=string)
..................................................
Target: tf.Tensor(0, shape=(), dtype=int64)
--------------------------------------------------
2022-04-08 09:30:11.645198: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.
Data preprocessing#
First, we need to decide how to represent the text data
TextVectorization#
We will be working with raw text (natural language inputs)
So we will use the
TextVectorizationlayer.It transforms a batch of strings (one example = one string) into either a
list of token indices (one example = 1D tensor of integer token indices) or
dense representation (one example = 1D tensor of float values representing data about the example’s tokens).
TextVectorizationsteps:
Standardize each example (usually lowercasing + punctuation stripping)
Split each example into substrings (usually words)
Recombine substrings into tokens (usually ngrams)
Index tokens (associate a unique int value with each token)
Transform each example using this index, either into a vector of ints or a dense float vector.
Multi-hot encoding#
Multi-hot encoding: only consider the presence or absence of terms in the review.
For example:
layer vocabulary is [‘movie’, ‘good’, ‘bad’]
a review read ‘This movie was bad.’
We would encode this as [1, 0, 1]
where movie (the first vocab term) and bad (the last vocab term) are present.
Create a
TextVectorizationlayer with multi-hot output and a max of 2500 tokensMap over our training dataset and discard the integer label indicating a positive or negative review (this gives us a dataset containing only the review text)
adapt()the layer over this dataset, which causes the layer to learn a vocabulary of the most frequent terms in all documents, capped at a max of 2500.
Adaptis a utility function on all stateful preprocessing layers, which allows layers to set their internal state from input data.Calling adapt is always optional.
For TextVectorization, we could instead supply a precomputed vocabulary on layer construction, and skip the adapt step.
text_vectorizer = layers.TextVectorization(
output_mode='multi_hot',
max_tokens=2500
)
features = train_ds.map(lambda x, y: x)
text_vectorizer.adapt(features)
Next, we define a preprocessing function
This is especially useful if you combine multiple preprocessing steps
Here, we only use one step:
preprocessconverts raw input data to the representation we want for our model
def preprocess(x):
return text_vectorizer(x)
Model#
Architecture#
inputs = keras.Input(shape=(1,), dtype='string')
outputs = layers.Dense(1)(preprocess(inputs))
model = keras.Model(inputs, outputs)
Compile#
model.compile(
optimizer='adam',
loss=losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy']
)
Show model summary
model.summary()
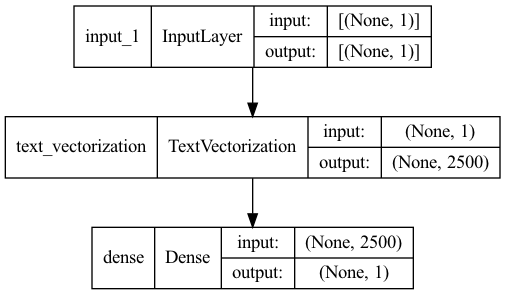
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 1)] 0
text_vectorization (TextVec (None, 2500) 0
torization)
dense (Dense) (None, 1) 2501
=================================================================
Total params: 2,501
Trainable params: 2,501
Non-trainable params: 0
_________________________________________________________________
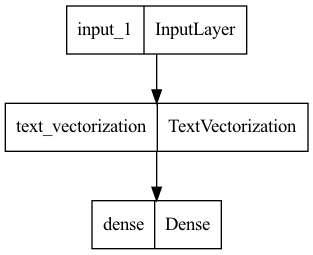
Let’s visualize the topology of the model
keras.utils.plot_model(model, "sentiment_classifier.png")
keras.utils.plot_model(model, "sentiment_classifier_with_shape_info.png", show_shapes=True)
Training#
We can now train a simple model on top of this multi-hot encoding.
First, we set up TensorBoard and an early stopping rule:
Define the directory where TensorBoard stores log files (we create folders with timestamps by using
datetime)We add
keras.callbacks.TensorBoardcallback which ensures that logs are created and stored.To prevent overfitting, we use a callback wich will stop the training when there is no improvement in the validation accuracy for three consecutive epochs.
# Create TensorBoard folders
log_dir = "logs/fit/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
# Create callbacks
my_callbacks = [
keras.callbacks.TensorBoard(log_dir=log_dir),
keras.callbacks.EarlyStopping(monitor='val_loss', patience=3),
]
Model training:
Train the model for 10 epochs in mini-batches of 512 samples
We shuffle the data and use a
buffer_sizeof 10000We monitor the model’s loss and accuracy on the 10,000 samples from the validation set.
buffer_size is the number of items in the shuffle buffer. The function fills the buffer and then randomly samples from it. A big enough buffer is needed for proper shuffling, but it’s a balance with memory consumption. Reshuffling happens automatically at every epoch
epochs = 10
history = model.fit(
train_ds.shuffle(buffer_size=10000).batch(512),
epochs=epochs,
validation_data=val_ds.batch(512),
callbacks=my_callbacks,
verbose=1)
Epoch 1/10
30/30 [==============================] - 2s 47ms/step - loss: 0.6570 - accuracy: 0.5297 - val_loss: 0.6073 - val_accuracy: 0.5627
Epoch 2/10
30/30 [==============================] - 1s 37ms/step - loss: 0.5713 - accuracy: 0.6363 - val_loss: 0.5444 - val_accuracy: 0.6579
Epoch 3/10
30/30 [==============================] - 1s 33ms/step - loss: 0.5153 - accuracy: 0.7089 - val_loss: 0.5018 - val_accuracy: 0.7496
Epoch 4/10
30/30 [==============================] - 1s 32ms/step - loss: 0.4754 - accuracy: 0.7583 - val_loss: 0.4695 - val_accuracy: 0.7693
Epoch 5/10
30/30 [==============================] - 1s 32ms/step - loss: 0.4448 - accuracy: 0.7877 - val_loss: 0.4459 - val_accuracy: 0.7763
Epoch 6/10
30/30 [==============================] - 1s 32ms/step - loss: 0.4208 - accuracy: 0.8054 - val_loss: 0.4264 - val_accuracy: 0.8006
Epoch 7/10
30/30 [==============================] - 1s 32ms/step - loss: 0.4009 - accuracy: 0.8233 - val_loss: 0.4112 - val_accuracy: 0.8137
Epoch 8/10
30/30 [==============================] - 1s 32ms/step - loss: 0.3846 - accuracy: 0.8366 - val_loss: 0.3984 - val_accuracy: 0.8198
Epoch 9/10
30/30 [==============================] - 1s 32ms/step - loss: 0.3707 - accuracy: 0.8443 - val_loss: 0.3883 - val_accuracy: 0.8183
Epoch 10/10
30/30 [==============================] - 1s 32ms/step - loss: 0.3589 - accuracy: 0.8509 - val_loss: 0.3790 - val_accuracy: 0.8269
Show number of epochs:
len(history.history['loss'])
10
Evaluation#
Loss and accuracy#
Show loss and accuracy for test data
results = model.evaluate(test_ds.batch(512), verbose=2)
for name, value in zip(model.metrics_names, results):
print("%s: %.3f" % (name, value))
49/49 - 1s - loss: 0.3829 - accuracy: 0.8246 - 1s/epoch - 21ms/step
loss: 0.383
accuracy: 0.825
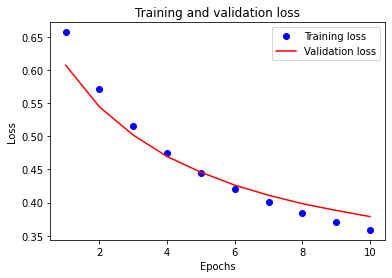
Create a plot of accuracy and loss over time
model.fit()returns a history object that contains a dictionary with everything that happened during training.
history_dict = history.history
history_dict.keys()
dict_keys(['loss', 'accuracy', 'val_loss', 'val_accuracy'])
There are four entries: one for each monitored metric during training and validation.
You can use these to plot the training and validation loss for comparison, as well as the training and validation accuracy:
acc = history_dict['accuracy']
val_acc = history_dict['val_accuracy']
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(acc) + 1)
# "bo" is for "blue dot"
plt.plot(epochs, loss, 'bo', label='Training loss')
# r is for "solid red line"
plt.plot(epochs, val_loss, 'r', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'r', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(loc='lower right')
plt.show()
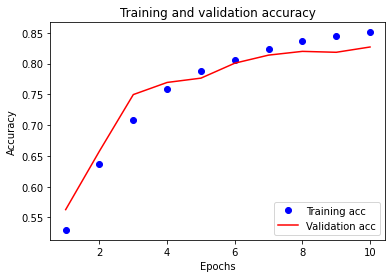
Blue dots represent the training loss and accuracy
Solid red lines are the validation loss and accuracy.
Training loss decreases with each epoch
Training accuracy increases with each epoch.
This is expected when using a gradient descent optimization
It should minimize the desired quantity on every iteration.
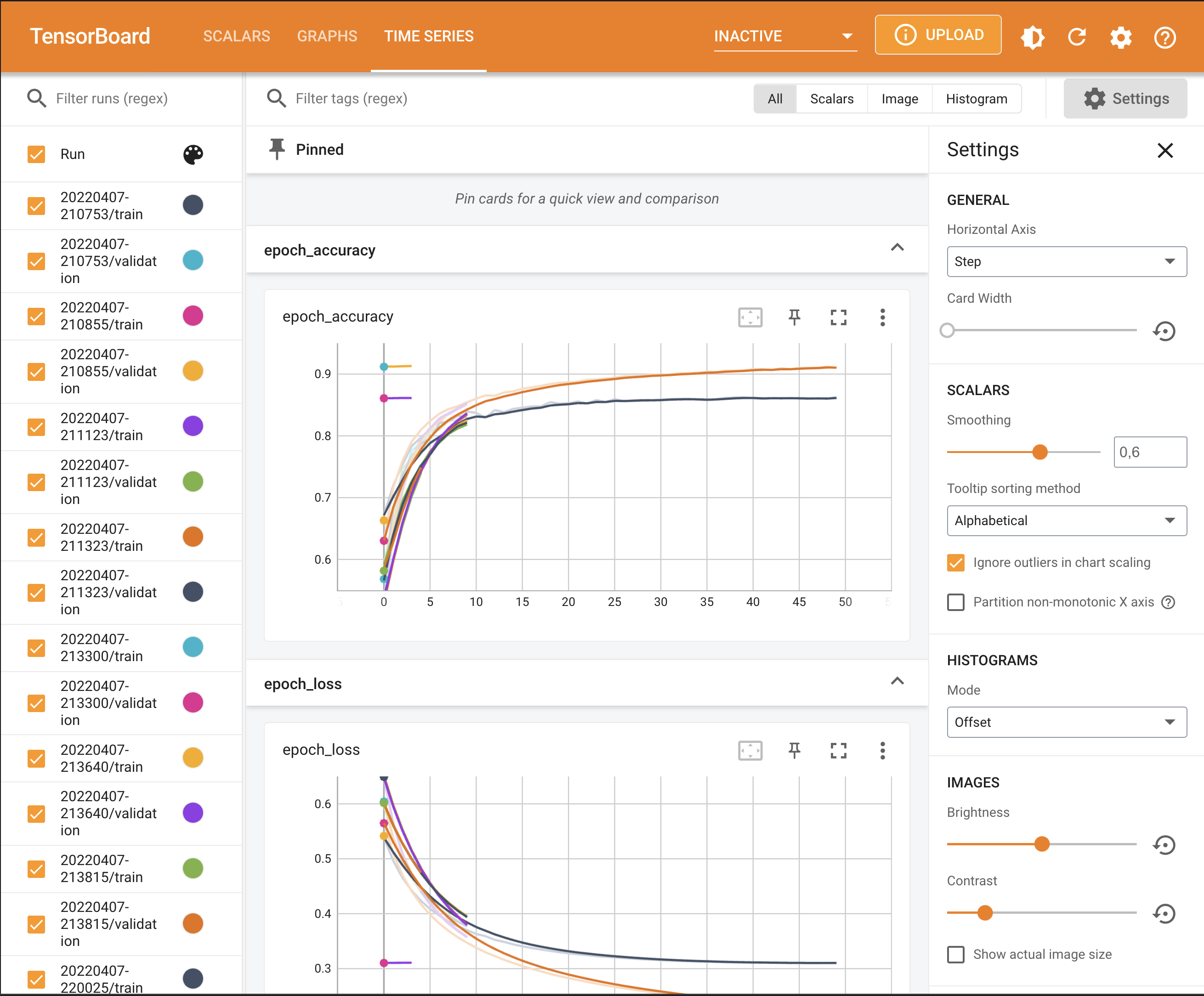
TensorBoard#
We use the tensorboard.notebook API
# Initiate TensorBoard
%tensorboard --logdir /logs/fit
# View open TensorBoard instances
notebook.list()
Known TensorBoard instances:
- port 6006: logdir logs/fit (started 0:21:34 ago; pid 2825)
# If no port is provided, the most recently launched TensorBoard is used
# notebook.display(port=6006, height=1000)
Alternative option to view TensorBoard:
How to use TensorBoard in Visual Studio Code (Stackoverflow):
Open the command palette (Ctrl/Cmd + Shift + P)
Search for the command “Python: Launch TensorBoard” and press enter.
Select the folder where your TensorBoard log files are located:
Select folder
logs/fit
Inference on new data#
Create new example data
examples = [
"The movie was great!",
"The movie was okay.",
"The movie was terrible..."
]
Add a sigmoid activation layer to our model to obtain probabilities
probability_model = keras.Sequential([
model,
layers.Activation('sigmoid')
])
Make predictions
probability_model.predict(examples)
array([[0.53673124],
[0.44737166],
[0.41206655]], dtype=float32)
Save model#
A Keras model consists of multiple components:
The architecture, or configuration, which specifies what layers the model contain, and how they’re connected.
A set of weights values (the “state of the model”).
An optimizer (defined by compiling the model).
A set of losses and metrics (defined by compiling the model or calling add_loss() or add_metric()).
The Keras model saving API makes it possible to save all of these pieces to disk at once, or to only selectively save some of them:
Saving everything into a single archive in the TensorFlow SavedModel format (or in the older Keras H5 format). This is the standard practice.
Saving the architecture / configuration only, typically as a JSON file.
Saving the weights values only. This is generally used when training the model.
We will save the complete model as Tensorflow SavedModel
model.save('imdb_model')
2022-04-08 09:30:31.623865: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them.
INFO:tensorflow:Assets written to: imdb_model/assets
INFO:tensorflow:Assets written to: imdb_model/assets
Load model#
model_new = load_model('imdb_model')
model_new.summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 1)] 0
text_vectorization (TextVec (None, 2500) 0
torization)
dense (Dense) (None, 1) 2501
=================================================================
Total params: 2,501
Trainable params: 2,501
Non-trainable params: 0
_________________________________________________________________
Multiple feature engineering steps#
The following code is an add on to demonstrate how to perform further feature engineering
Let’s experiment with a new feature
Our multi-hot encoding does not contain any notion of review length
We can try adding a feature for normalized string length.
Create the normalization layer (which will scale the input to have 0 mean and 1 standard deviation)
Adapt it to our input
Within the preprocess function, we simply concatenate our multi-hot encoding and length features together
# This layer will scale our review length feature to mean 0 variance 1.
normalizer = layers.Normalization(axis=None)
normalizer.adapt(features.map(lambda x: tf.strings.length(x)))
def preprocess(x):
multi_hot_terms = text_vectorizer(x)
normalized_length = normalizer(tf.strings.length(x))
# Combine the multi-hot encoding with review length.
return layers.concatenate((multi_hot_terms, normalized_length))
Use the new preprocess function in our model (we don’t use TensorBoard in this example):
inputs = tf.keras.Input(shape=(1,), dtype='string')
outputs = layers.Dense(1)(preprocess(inputs))
model = tf.keras.Model(inputs, outputs)
model.compile(loss=tf.keras.losses.BinaryCrossentropy(from_logits=True))
epochs = 5
callback = keras.callbacks.EarlyStopping(monitor='val_loss', patience=3)
history = model.fit(
train_ds.shuffle(buffer_size=10000).batch(512),
epochs=epochs,
validation_data=val_ds.batch(512),
callbacks=[callback],
verbose=1)
Epoch 1/5
30/30 [==============================] - 1s 37ms/step - loss: 0.6334 - val_loss: 0.5907
Epoch 2/5
30/30 [==============================] - 1s 34ms/step - loss: 0.5522 - val_loss: 0.5304
Epoch 3/5
30/30 [==============================] - 1s 34ms/step - loss: 0.4986 - val_loss: 0.4870
Epoch 4/5
30/30 [==============================] - 1s 34ms/step - loss: 0.4581 - val_loss: 0.4548
Epoch 5/5
30/30 [==============================] - 1s 34ms/step - loss: 0.4265 - val_loss: 0.4296