Feature selection
Contents
Feature selection#
The following content is mainly based on scikit learn documentations:
Model-based and sequential feature selection from Manoj Kumar, Maria Telenczuk and Nicolas Hug.
Common pitfalls in the interpretation of coefficients of linear models
Prepara data#
We use a data frame of major league baseball players to predict their salaries from some career statistics (more information about data). Note that the data is already preprocessed.
To get an overview about the data preparation, visit this tutorial.
import pandas as pd
# import data
df = pd.read_csv("https://raw.githubusercontent.com/kirenz/datasets/master/hitters-clean.csv")
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 263 entries, 0 to 262
Data columns (total 20 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 AtBat 263 non-null float64
1 Hits 263 non-null float64
2 HmRun 263 non-null float64
3 Runs 263 non-null float64
4 RBI 263 non-null float64
5 Walks 263 non-null float64
6 Years 263 non-null float64
7 CAtBat 263 non-null float64
8 CHits 263 non-null float64
9 CHmRun 263 non-null float64
10 CRuns 263 non-null float64
11 CRBI 263 non-null float64
12 CWalks 263 non-null float64
13 PutOuts 263 non-null float64
14 Assists 263 non-null float64
15 Errors 263 non-null float64
16 Salary 263 non-null float64
17 League_N 263 non-null int64
18 Division_W 263 non-null int64
19 NewLeague_N 263 non-null int64
dtypes: float64(17), int64(3)
memory usage: 41.2 KB
# create label
y = df['Salary']
# create features
X = df.drop(['Salary'], axis=1).astype(float)
# create list of feature names
feature_names = X.columns
from sklearn.model_selection import train_test_split
# data split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=10)
from sklearn.preprocessing import StandardScaler
# make list of numerical features (League_N, Division_W and NewLeague_N are categorcial)
list_numerical = X.drop(['League_N', 'Division_W', 'NewLeague_N'], axis=1).columns
# standardize numerical features
scaler = StandardScaler().fit(X_train[list_numerical])
X_train[list_numerical] = scaler.transform(X_train[list_numerical])
X_test[list_numerical] = scaler.transform(X_test[list_numerical])
Model#
We fit a lasso regression with 5-fold cross validation to choose the best regularization parameter based on the mean squared error:
from sklearn.linear_model import LassoCV
reg = LassoCV(cv=5, random_state=10, max_iter=10000).fit(X_train, y_train)
# show best alpha parameter
reg.alpha_
2.3441244939374593
Show feature importance:
import seaborn as sns
import numpy as np
# get absolute values of coefficients
importance = np.abs(reg.coef_)
sns.barplot(x=importance,
y=feature_names);
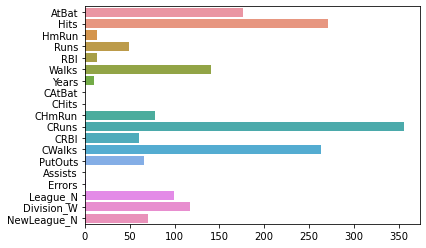
Feature selection#
Filter method#
In this example, we use feature importance as a filter to select our features. In particular, we want to select the two features which are the most important according to the coefficients. The function SelectFromModel is meant just for that. SelectFromModel accepts a threshold parameter and will select the features whose importance (defined by the coefficients) are above this threshold.
In our case, we want to select only 2 features. Hence, we will set the threshold slightly above the coefficient of the third most important feature. We also record the time the algorithm takes to obtain the results.
from sklearn.feature_selection import SelectFromModel
from time import time
# set threshold
threshold = np.sort(importance)[-3] + 1
# obtain time
tic = time()
# fit model
sfm = SelectFromModel(reg, threshold=threshold).fit(X_train, y_train)
# obtain time
toc = time()
# print results
print(f"Features selected by SelectFromModel: {feature_names[sfm.get_support()]}")
print(f"Done in {toc - tic:.3f}s")
Features selected by SelectFromModel: Index(['Hits', 'CRuns'], dtype='object')
Done in 0.121s
Wrapper method#
Another way of selecting features is to use a (greedy) wrapper method with scikit learn’s SequentialFeatureSelector (SFS). SFS is a greedy procedure where, at each iteration, we choose the best new feature to add to our selected features based a cross-validation score:
Forward-Selection: That is, we start with 0 features and choose the best single feature with the highest score. The procedure is repeated until we reach the desired number of selected features.Backward selection: We can also go in the reverse direction (backward SFS), i.e. start with all the features and greedily choose features to remove one by one. We illustrate both approaches here.
Forward selection#
from sklearn.feature_selection import SequentialFeatureSelector
tic_fwd = time()
sfs_forward = SequentialFeatureSelector(
reg, n_features_to_select=2,
direction="forward").fit(X_train, y_train)
toc_fwd = time()
print(
"Features selected by forward sequential selection: "
f"{feature_names[sfs_forward.get_support()]}"
)
print(f"Done in {toc_fwd - tic_fwd:.3f}s")
Features selected by forward sequential selection: Index(['Hits', 'CRBI'], dtype='object')
Done in 6.094s
Backward selection#
tic_bwd = time()
sfs_backward = SequentialFeatureSelector(
reg, n_features_to_select=2,
direction="backward").fit(X_train, y_train)
toc_bwd = time()
print(
"Features selected by backward sequential selection: "
f"{feature_names[sfs_backward.get_support()]}"
)
print(f"Done in {toc_bwd - tic_bwd:.3f}s")
Features selected by backward sequential selection: Index(['Walks', 'CRuns'], dtype='object')
Done in 56.492s
Discussion#
Note that:
SelectFromModelis significantly faster than SFS sinceSelectFromModelonly needs to fit a model once, while SFS needs to cross-validate many different models for each of the iterations.SFS however works with any model, while
SelectFromModelrequires the underlying estimator to expose acoef_attribute or afeature_importances_attribute.Forward selection is much faster than backward selection because it only needs to perform
n_features_to_select = 2iterations, while the backward selection needs to performn_features-n_features_to_select.